前言
MapReduce作为Hadoop的编程框架,对于大数据开发或者想要接触大数据开发的学习者来说,是必须要掌握的。MapReduce计算模型主要由三个阶段构成:Map、shuffle、Reduce。Map是映射,负责数据的过滤分法,将原始数据转化为键值对;Reduce是合并,将具有相同key值的value进行处理后再输出新的键值对作为最终结果。为了让Reduce可以并行处理Map的结果,必须对Map的输出进行一定的排序与分割,然后再交给对应的Reduce,而这个将Map输出进行进一步整理并交给Reduce的过程就是Shuffle。Shuffle过程包含在Map和Reduce两端,即Map shuffle和Reduce shuffle,shuffle的操作是针对map输出的结果(key value)。
概述
- shuffle过程
- map() 输出
- map shuffle phase
- reduce shuffle phase
- 输入reduce()
- shuffle
- partition 分区
- sort 排序
- combiner map端的reduce
- group 分组
- compress 压缩 通过mapreduce程序可以设定,配置文件
shuffle的详解
- shuffle的操作是针对map输出的结果(key value)
- map shuffle
环形缓冲区:
默认大小:100MB 配置
mapred-site.xml: mapreduce.task.io.sort.mb进入环形缓冲区,当达到缓冲区的80%,进行一次溢写,spill到本地磁盘上 并不是立刻写入磁盘,而是要经过- partition(分区):
依据 mapreduce job 中的
job.setNumReduceTasks(2)进行设置,进行分区 决定 map 输出的数据被哪一个 reduce 任务 进行处理分析 默认情况下, 使用的类是HashPartitionergetPartition() (key.hashCode()&Integer.MAX_VALUE) % numReduceTasks; key.hashCode() & Integer.MAX_VALUE 保证结果是一个整数 value % numReduceTasks(默认为1) 0 - sort 对 partition 的数据进行排序
- spill到磁盘 形成多个小文件 最终要合并
- combiner map 端的 reduce, 减少 map 输出的数据,减少了键值对 减少 map 输出的键值对,磁盘io 减少 reduce 拉取的数据, 网络io
- compress 压缩(可配置,依据经验,测试:正态分布图) 压缩: 减少网络io,磁盘io 消耗cpu等资源
- partition(分区):
依据 mapreduce job 中的
- reduce shuffle
- merge 合并
相同分区的数据合并在一起(map task 处理完成数据后,通知
app master, 然后app master通过所有的reduce task,主动的拉去 map task的本地数据,拉取到自己分区中)。 - 排序 对各个分区的数据进行排序。
- 分组
将相同的key的value值,存入到一个集合中,形成一个
<key,[1,1,1,2]>; 将key/values传递给 reduce 函数。
- merge 合并
相同分区的数据合并在一起(map task 处理完成数据后,通知
reduce()参数为 map task处理结果
归纳
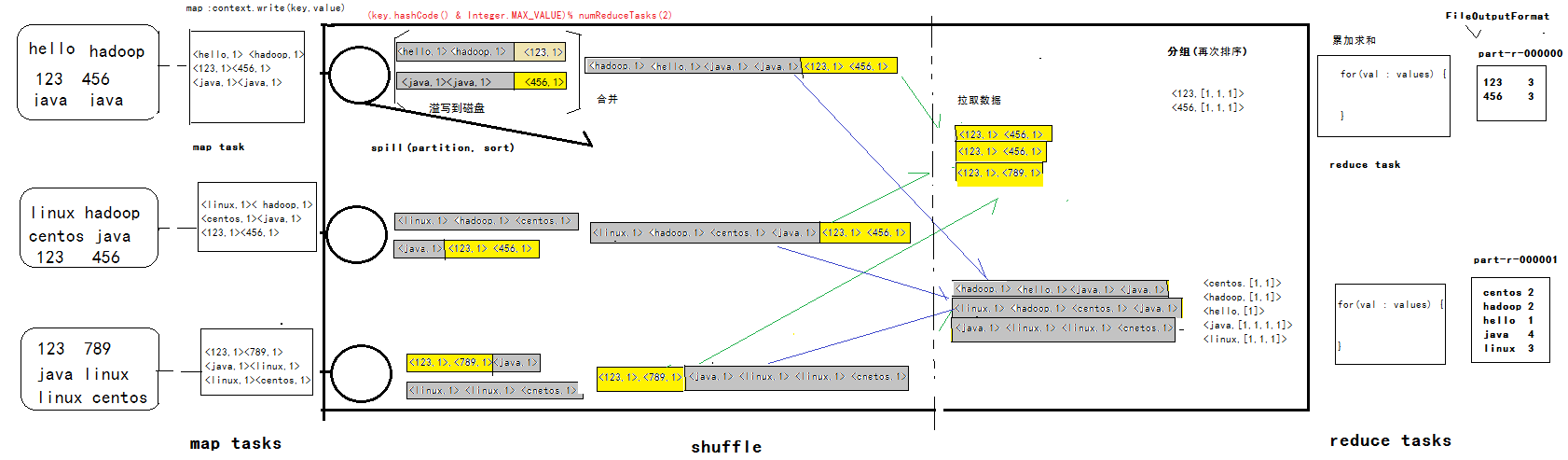
以上是我个人对 shuffle 过程的理解, 下面是我对整个过程的理解示意图, 对如有不对之处欢迎指正。